p4-mapreduce
Walk-through example
This document walks step-by-step through an example MapReduce job. Our staff Manager and Worker solutions produce logging output so you can see what’s going on.
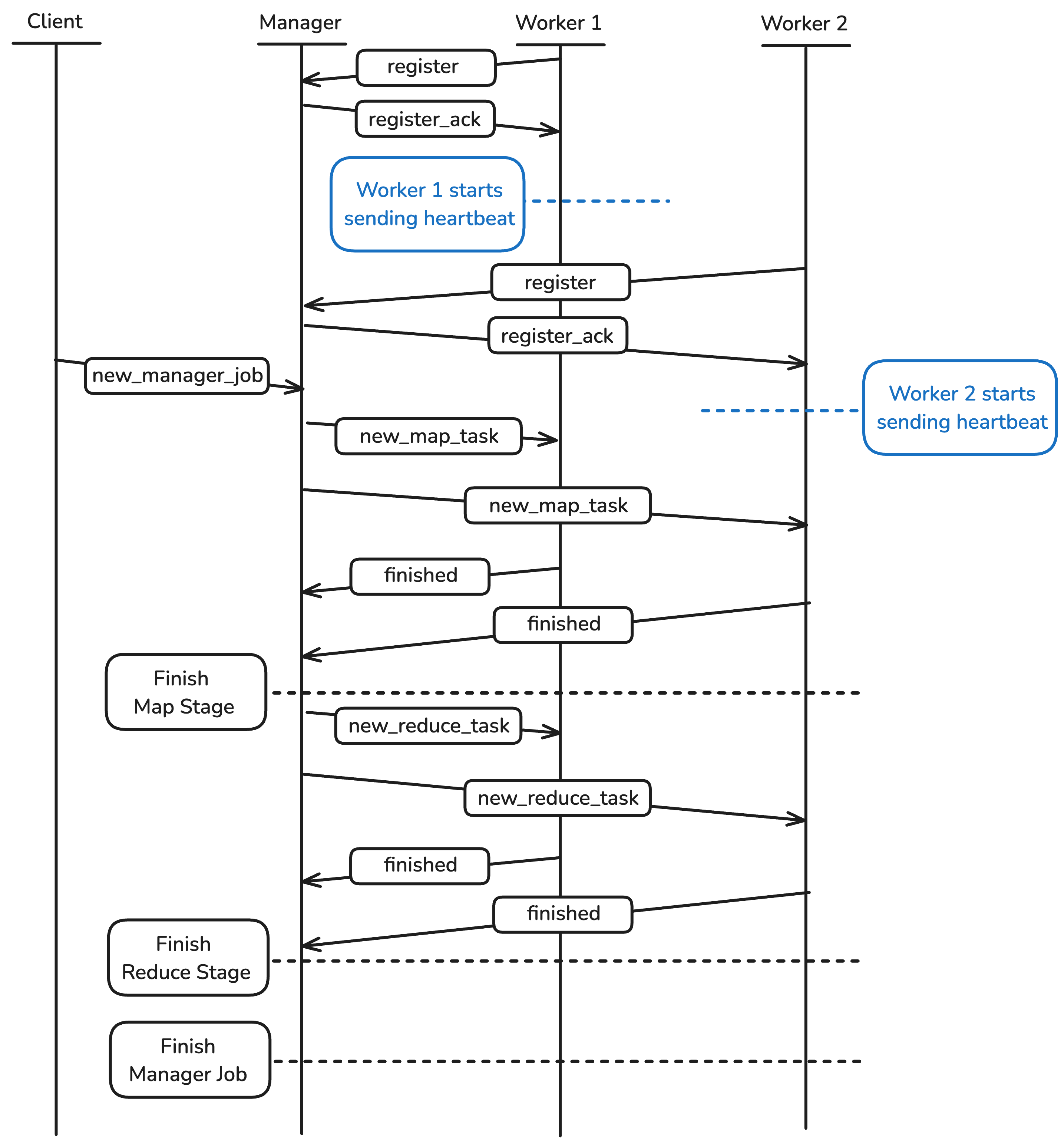
Here’s an overview of the messages between the Client, Manager and Worker.
Files
Start in your project root directory. Take a look at a few of the input files.
$ pwd
/Users/awdeorio/src/eecs485/p4-mapreduce
$ ls tests/testdata/input_small
file01 file02
$ cat tests/testdata/input_small/file01
hello world
hello eecs485
$ cat tests/testdata/input_small/file02
goodbye autograder
hello autograder
We’re going to run a word count job. Start by simulating the MapReduce job at the command line. This is the expected output. Save it to a file.
$ cat tests/testdata/input_small/* | tests/testdata/exec/wc_map.sh | sort | tests/testdata/exec/wc_reduce.sh
autograder 2
eecs485 1
goodbye 1
hello 3
world 1
$ cat tests/testdata/input_small/* | tests/testdata/exec/wc_map.sh | sort | tests/testdata/exec/wc_reduce.sh > correct.txt
These are the files we have before starting the server.
$ pwd
/Users/awdeorio/src/eecs485/p4-mapreduce
$ ls
bin mapreduce mapreduce.egg-info requirements.txt pyproject.toml tests
Start Manager
Kill any stale MapReduce processes.
$ pkill -lf mapreduce- # macOS
$ pkill -f mapreduce- # Linux/WSL
Start the Manager.
$ mapreduce-manager --loglevel=DEBUG
Manager:6000 [INFO] Starting manager:6000
Manager:6000 [INFO] PWD /Users/awdeorio/src/eecs485/p4-mapreduce
Manager:6000 [INFO] Created /tmp/mapreduce-shared-k7kc6ux9
The Manager created a shared temporary directory /tmp/mapreduce-shared-k7kc6ux9. We’re using the Python standard library tempfile.TemporaryDirectory to create and automatically clean up the temporary directory, so your path could be different.
Start Workers
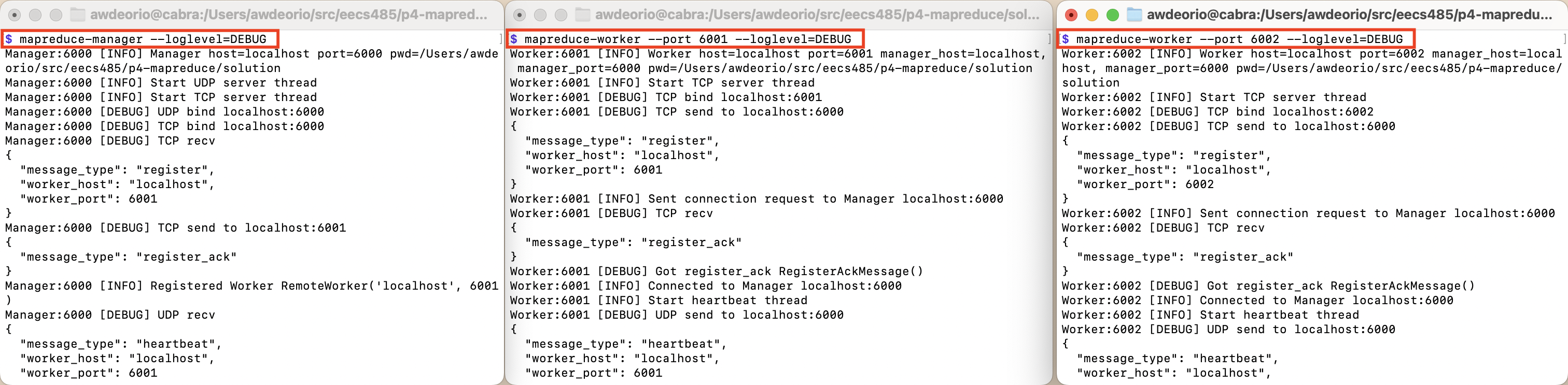
Start two Workers in separate terminals.
$ mapreduce-worker --port 6001 --loglevel=DEBUG # Terminal 2
Worker:6001 [INFO] Starting worker:6001
Worker:6001 [INFO] PWD /Users/awdeorio/src/eecs485/p4-mapreduce
Manager:6000 [DEBUG] received
{
"message_type": "register",
"worker_host": "localhost",
"worker_port": 6001,
}
Manager:6000 [INFO] registered worker localhost:6001
Worker:6001 [DEBUG] received
{
"message_type": "register_ack"
}
$ mapreduce-worker --port 6002 --loglevel=DEBUG # Terminal 3
Worker:6002 [INFO] Starting worker:6002
Worker:6002 [INFO] PWD /Users/awdeorio/src/eecs485/p4-mapreduce
Manager:6000 [DEBUG] received
{
"message_type": "register",
"worker_host": "localhost",
"worker_port": 6002,
}
Manager:6000 [INFO] registered worker localhost:6002
Worker:6002 [DEBUG] received
{
"message_type": "register_ack"
}
$
At this point, you’ll have 3 terminals open for the Manager and two Workers.
Pro-tip To produce logging output similar to the instructor solution, see the Logging section of the spec.
Submit a MapReduce job
Submit a word count job in a fourth terminal. We’re taking advantage of the submit defaults, see mapreduce-submit --help for more info.
$ mapreduce-submit -i tests/testdata/input_small
Submitted job to Manager localhost:6000
input directory tests/testdata/input_small
output directory output
mapper executable tests/testdata/exec/wc_map.sh
reducer executable tests/testdata/exec/wc_reduce.sh
num mappers 2
num reducers 2
The Manager receives the job.
Manager:6000 [DEBUG] received
{
"message_type": "new_manager_job",
"input_directory": "tests/testdata/input_small",
"output_directory": "output",
"mapper_executable": "tests/testdata/exec/wc_map.sh",
"reducer_executable": "tests/testdata/exec/wc_reduce.sh",
"num_mappers": 2,
"num_reducers": 2
}
Manager:6000 [INFO] Created output
Manager:6000 [INFO] Created /tmp/mapreduce-shared-k7kc6ux9/job-00000
The Manager created a final output directory output and a job-00000 directory for intermediate files inside of the shared temporary directory.
Map Stage
The Map Stage runs.
Manager:6000 [INFO] Begin Map Stage
Worker:6001 [DEBUG] received
{
"message_type": "new_map_task",
"task_id": 0,
"input_paths": [
"tests/testdata/input_small/file01"
],
"executable": "tests/testdata/exec/wc_map.sh",
"output_directory": "/tmp/mapreduce-shared-k7kc6ux9/job-00000",
"num_partitions": 2
}
Worker:6002 [DEBUG] received
{
"message_type": "new_map_task",
"task_id": 1,
"input_paths": [
"tests/testdata/input_small/file02"
],
"executable": "tests/testdata/exec/wc_map.sh",
"output_directory": "/tmp/mapreduce-shared-k7kc6ux9/job-00000",
"num_partitions": 2
}
Worker:6001 [INFO] Created /tmp/mapreduce-local-task00000-pe6k0epd
Worker:6001 [INFO] Executed tests/testdata/exec/wc_map.sh input=tests/testdata/input_small/file01
Worker:6001 [INFO] Sorted /tmp/mapreduce-local-task00000-pe6k0epd/maptask00000-part00000
Worker:6001 [INFO] Sorted /tmp/mapreduce-local-task00000-pe6k0epd/maptask00000-part00001
Worker:6001 [INFO] Moved /tmp/mapreduce-local-task00000-pe6k0epd/maptask00000-part00000 -> /tmp/mapreduce-shared-k7kc6ux9/job-00000/maptask00000-part00000
Worker:6001 [INFO] Moved /tmp/mapreduce-local-task00000-pe6k0epd/maptask00000-part00001 -> /tmp/mapreduce-shared-k7kc6ux9/job-00000/maptask00000-part00001
Worker:6001 [INFO] Removed /tmp/mapreduce-local-task00000-pe6k0epd
Manager:6000 [DEBUG] received
{
"message_type": "finished",
"task_id": 0,
"worker_host": "localhost",
"worker_port": 6001
}
Worker:6002 [INFO] Created /tmp/mapreduce-local-task00001-mev01saa
Worker:6002 [INFO] Executed tests/testdata/exec/wc_map.sh input=tests/testdata/input_small/file02
Worker:6002 [INFO] Sorted /tmp/mapreduce-local-task00001-mev01saa/maptask00001-part00000
Worker:6002 [INFO] Sorted /tmp/mapreduce-local-task00001-mev01saa/maptask00001-part00001
Worker:6002 [INFO] Moved /tmp/mapreduce-local-task00001-mev01saa/maptask00001-part00000 -> /tmp/mapreduce-shared-k7kc6ux9/job-00000/maptask00001-part00000
Worker:6002 [INFO] Moved /tmp/mapreduce-local-task00001-mev01saa/maptask00001-part00001 -> /tmp/mapreduce-shared-k7kc6ux9/job-00000/maptask00001-part00001
Worker:6002 [INFO] Removed /tmp/mapreduce-local-task00001-mev01saa
Manager:6000 [DEBUG] received
{
"message_type": "finished",
"task_id": 1,
"worker_host": "localhost",
"worker_port": 6002
}
Manager:6000 [INFO] End Map Stage
Note how the Workers created local temporary directories of their own for each task, and then moved the output files into the Manager’s shared temporary directory when they finished writing and sorting.
At the end of the Map Stage, mapping, partitioning, and sorting is complete. In this example, the Manager’s shared temporary directory (e.g., /tmp/mapreduce-shared-XYZ123/job-00000) contains 4 files. To see these files during debugging, set a breakpoint before the Manager’s shared temporary directory is deleted.
hello 1
hello 1
eecs485 1
world 1
hello 1
autograder 1
autograder 1
goodbye 1
With 2 reducers, we have 2 partitions. For example when map task 0 computes md5("hello") % 2 == 0, this key goes in partition 0, maptask00000-part00000. Similarly, when map task 1 computes md5("hello") % 2 == 0, this key goes in partition 0, maptask00001-part00000.
Reduce Stage
Finally, the Reduce Stage runs.
Manager:6000 [INFO] begin Reduce Stage
Worker:6001 [DEBUG] received
{
"message_type": "new_reduce_task",
"task_id": 0,
"input_paths": [
"/tmp/mapreduce-shared-k7kc6ux9/job-00000/maptask00000-part00000",
"/tmp/mapreduce-shared-k7kc6ux9/job-00000/maptask00001-part00000"
],
"executable": "tests/testdata/exec/wc_reduce.sh",
"output_directory": "output"
}
Worker:6002 [DEBUG] received
{
"message_type": "new_reduce_task",
"task_id": 1,
"input_paths": [
"/tmp/mapreduce-shared-k7kc6ux9/job-00000/maptask00000-part00001",
"/tmp/mapreduce-shared-k7kc6ux9/job-00000/maptask00001-part00001"
],
"executable": "tests/testdata/exec/wc_reduce.sh",
"output_directory": "output"
}
Worker:6001 [INFO] Created /tmp/mapreduce-local-task00000-9tjc90x8
Worker:6001 [INFO] Executed tests/testdata/exec/wc_reduce.sh
Worker:6001 [INFO] Moved /tmp/mapreduce-local-task00000-9tjc90x8/part-00000 -> output/part-00000
Worker:6001 [INFO] Removed /tmp/mapreduce-local-task00000-9tjc90x8
Manager:6000 [DEBUG] received
{
"message_type": "finished",
"task_id": 0,
"worker_host": "localhost",
"worker_port": 6001
}
Worker:6002 [INFO] Created /tmp/mapreduce-local-task00001-hqummo7a
Worker:6002 [INFO] Executed tests/testdata/exec/wc_reduce.sh
Worker:6002 [INFO] Moved /tmp/mapreduce-local-task00001-hqummo7a/part-00001 -> output/part-00001
Worker:6002 [INFO] Removed /tmp/mapreduce-local-task00001-hqummo7a
Manager:6000 [DEBUG] received
{
"message_type": "finished",
"task_id": 1,
"worker_host": "localhost",
"worker_port": 6002
}
Manager:6000 [INFO] end Reduce Stage
Manager:6000 [INFO] Removed /tmp/mapreduce-shared-k7kc6ux9/job-00000
Manager:6000 [INFO] Finished job. Output directory: output
Output
After the job is finished, we can see the final output inside output/.
$ tree output/
output/
├── part-00000
└── part-00001
hello 3
autograder 2
eecs485 1
goodbye 1
world 1
Recall that md5("hello") % 2 == 0, so this key is in partition 0 (part00000). Similarly, md5("autograder") % 2 == 1, so this key is in partition 1 (part00001).
Sort the output so that we can easily compare with the correct answer.
$ cat output/* | sort
autograder 2
eecs485 1
goodbye 1
hello 3
world 1
$ cat output/* | sort > actual.txt
$ diff correct.txt actual.txt
Shutdown
Finally, send a shutdown signal to the server.
$ mapreduce-submit --shutdown # Terminal 4
Manager:6000 [DEBUG] received
{
"message_type": "shutdown"
}
Manager:6000 [INFO] shutting down
Manager:6000 [INFO] Removed /tmp/mapreduce-shared-k7kc6ux9
Worker:6001 [DEBUG] received
{
"message_type": "shutdown"
}
Worker:6001 [INFO] shutting down
Worker:6002 [DEBUG] received
{
"message_type": "shutdown"
}
Worker:6002 [INFO] shutting down
After you run the shutdown command and get the above output, hit Enter.
You should see something similar to the following:
[1] Done mapreduce-manager
[2]- Done mapreduce-worker
[3]+ Done mapreduce-worker --port 6002
Verify that no MapReduce processes are running.
$ pgrep -lf mapreduce- # macOS
$ pgrep -af mapreduce- # Linux
Acknowledgments
This document is licensed under a Creative Commons Attribution-NonCommercial 4.0 License. You’re free to copy and share this document, but not to sell it. You may not share source code provided with this document.